This is what I did:
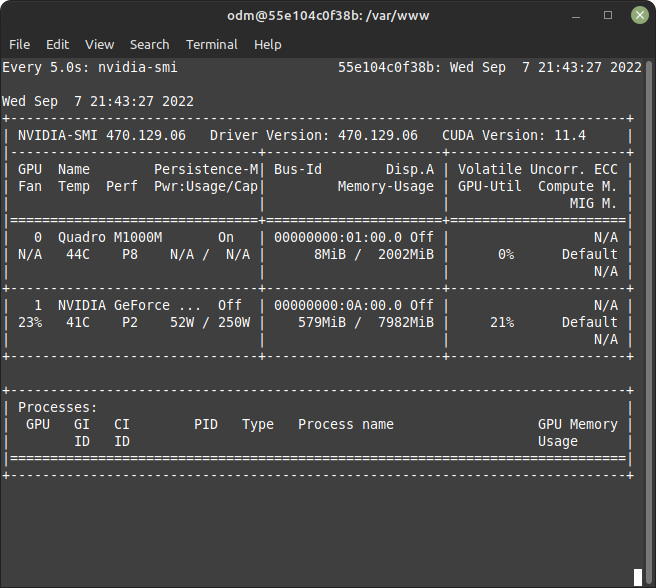
First nodeodm, tied to GPU 0:
Environment of first node:
odm@2d35d79bbbbe:/var/www$ env | grep 'NV.*'
NV_LIBCUBLAS_VERSION=11.3.1.68-1
NVIDIA_VISIBLE_DEVICES=0
NVIDIA_REQUIRE_CUDA=cuda>=11.2 brand=tesla,driver>=418,driver<419 brand=tesla,driver>=450,driver<451
NV_NVTX_VERSION=11.2.67-1
NV_LIBCUSPARSE_VERSION=11.3.1.68-1
NV_LIBNPP_VERSION=11.2.1.68-1
NVIDIA_DRIVER_CAPABILITIES=compute,utility
NV_LIBNPP_PACKAGE=libnpp-11-2=11.2.1.68-1
NV_CUDA_CUDART_VERSION=11.2.72-1
NV_LIBCUBLAS_PACKAGE=libcublas-11-2=11.3.1.68-1
NV_LIBCUBLAS_PACKAGE_NAME=libcublas-11-2
NV_CUDA_LIB_VERSION=11.2.0-1
NVARCH=x86_64
NV_CUDA_COMPAT_PACKAGE=cuda-compat-11-2
NV_LIBNCCL_PACKAGE=libnccl2=2.8.4-1+cuda11.2
NV_LIBNCCL_PACKAGE_NAME=libnccl2
NV_LIBNCCL_PACKAGE_VERSION=2.8.4-1
odm@2d35d79bbbbe:/var/www$
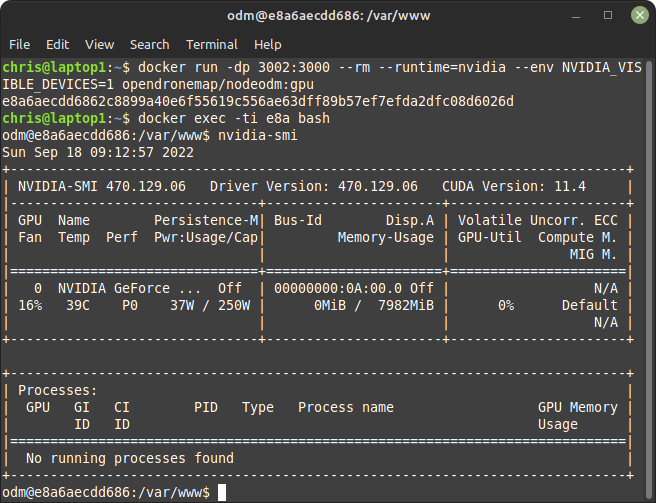
Second nodeodm, tied to GPU 1:
Environment of second node:
odm@e8a6aecdd686:/var/www$ env | grep 'NV.*'
NV_LIBCUBLAS_VERSION=11.3.1.68-1
NVIDIA_VISIBLE_DEVICES=1
NVIDIA_REQUIRE_CUDA=cuda>=11.2 brand=tesla,driver>=418,driver<419 brand=tesla,driver>=450,driver<451
NV_NVTX_VERSION=11.2.67-1
NV_LIBCUSPARSE_VERSION=11.3.1.68-1
NV_LIBNPP_VERSION=11.2.1.68-1
NVIDIA_DRIVER_CAPABILITIES=compute,utility
NV_LIBNPP_PACKAGE=libnpp-11-2=11.2.1.68-1
NV_CUDA_CUDART_VERSION=11.2.72-1
NV_LIBCUBLAS_PACKAGE=libcublas-11-2=11.3.1.68-1
NV_LIBCUBLAS_PACKAGE_NAME=libcublas-11-2
NV_CUDA_LIB_VERSION=11.2.0-1
NVARCH=x86_64
NV_CUDA_COMPAT_PACKAGE=cuda-compat-11-2
NV_LIBNCCL_PACKAGE=libnccl2=2.8.4-1+cuda11.2
NV_LIBNCCL_PACKAGE_NAME=libnccl2
NV_LIBNCCL_PACKAGE_VERSION=2.8.4-1
odm@e8a6aecdd686:/var/www$
Both nodes only see the assigned GPU.
Next starting WebODM:
chris@laptop1:~/FH/Master/Tools/WebODM$ ./webodm.sh start --default-nodes 0 --gpu
01:00.0 VGA compatible controller: NVIDIA Corporation GM107GLM [Quadro M1000M] (rev a2)
01:00.1 Audio device: NVIDIA Corporation GM107 High Definition Audio Controller [GeForce 940MX] (rev a1)
0a:00.0 VGA compatible controller: NVIDIA Corporation TU104 [GeForce RTX 2080 SUPER] (rev a1)
0a:00.1 Audio device: NVIDIA Corporation TU104 HD Audio Controller (rev a1)
0a:00.2 USB controller: NVIDIA Corporation TU104 USB 3.1 Host Controller (rev a1)
0a:00.3 Serial bus controller [0c80]: NVIDIA Corporation TU104 USB Type-C UCSI Controller (rev a1)
GPU_NVIDIA has been found
Checking for docker... OK
Checking for docker-compose... OK
Starting WebODM...
Using the following environment:
================================
Host: localhost
Port: 8000
Media directory: appmedia
SSL: NO
SSL key:
SSL certificate:
SSL insecure port redirect: 80
Celery Broker: redis://broker
Default Nodes: 0
================================
Make sure to issue a ./webodm.sh down if you decide to change the environment.
docker-compose -f docker-compose.yml up --remove-orphans
Removing orphan container "webodm_node-odm-1_1"
Removing orphan container "webodm_node-odm-2_1"
Removing orphan container "webodm_node-odm-3_1"
Starting db ... done
Starting broker ... done
Starting worker ... done
Starting webapp ... done
Attaching to db, broker, worker, webapp
...
webapp | Congratulations! └@(・◡・)@┐
webapp | ==========================
webapp |
webapp | If there are no errors, WebODM should be up and running!
webapp |
webapp | Open a web browser and navigate to http://localhost:8000
Starting clusterodm:
chris@laptop1:~$ docker run --rm -dp 3000:3000 -p 8081:8080 -p 10000:10000 opendronemap/clusterodm
7fbf9324d646e9782dbccf68b85331c8c5305e0bbf8371692073885a1fa175f9
chris@laptop1:~$ telnet localhost 8081
Trying ::1...
Connected to localhost.
Escape character is '^]'.
Welcome ::ffff:172.17.0.1:59704 ClusterODM:1.5.3
HELP for help
QUIT to quit
#> NODE LIST
#> NODE ADD 192.168.0.150 3001
OK
#> NODE ADD 192.168.0.150 3002
OK
#> NODE LIST
1) 192.168.0.150:3001 [online] [0/1] <engine: odm 2.8.8> <API: 2.2.0>
2) 192.168.0.150:3002 [online] [0/1] <engine: odm 2.8.8> <API: 2.2.0>
#>
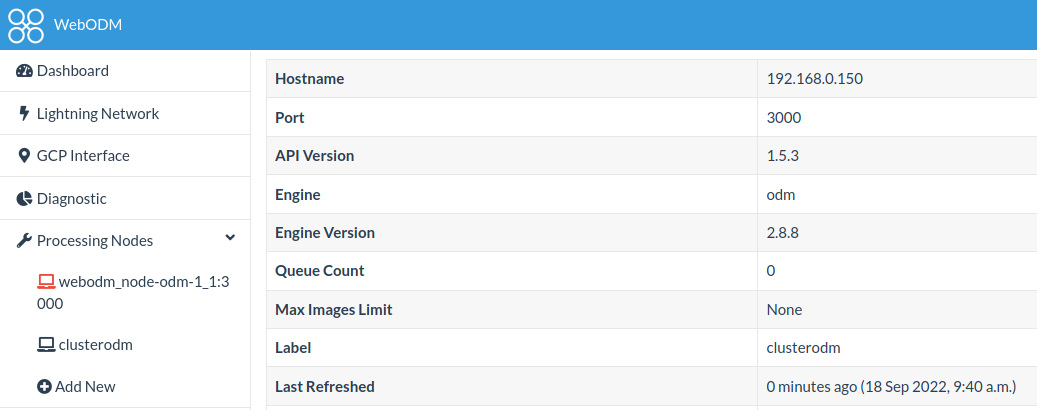
Adding clusterodm to WebODM:
And finally the dataset running on two nodeodm instances:
One thing I can think about is the Nvidia container runtime, which needs to be installed. The package is named nvidia-docker2. When I tied the GPUs with my initial post, I added the device node to the nvidia yml docker compose file. But if that makes a difference. The Nvidia runtime can be set as default using Dockers daemon.json file, according to this page:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/user-guide.html
At least this is how it works for me. Give it a try with the Nvidia runtime.