Last night as a job I’d submitted was nearing completion I found I could not access my server.
The server is Ubuntu, 16 CPU’s, 64gb RAM, 480 gb storage. It’s running on DigitalOcean.
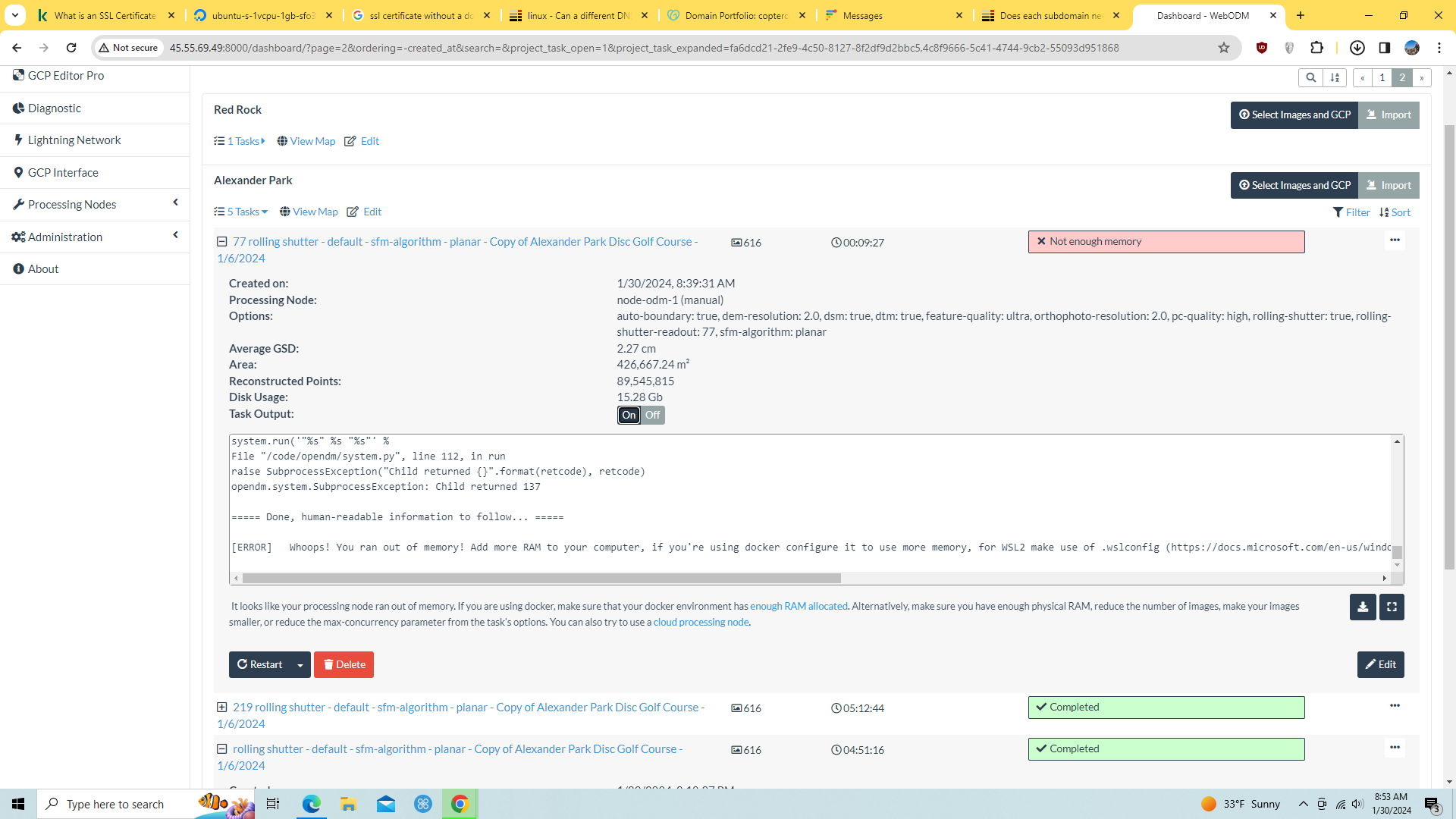
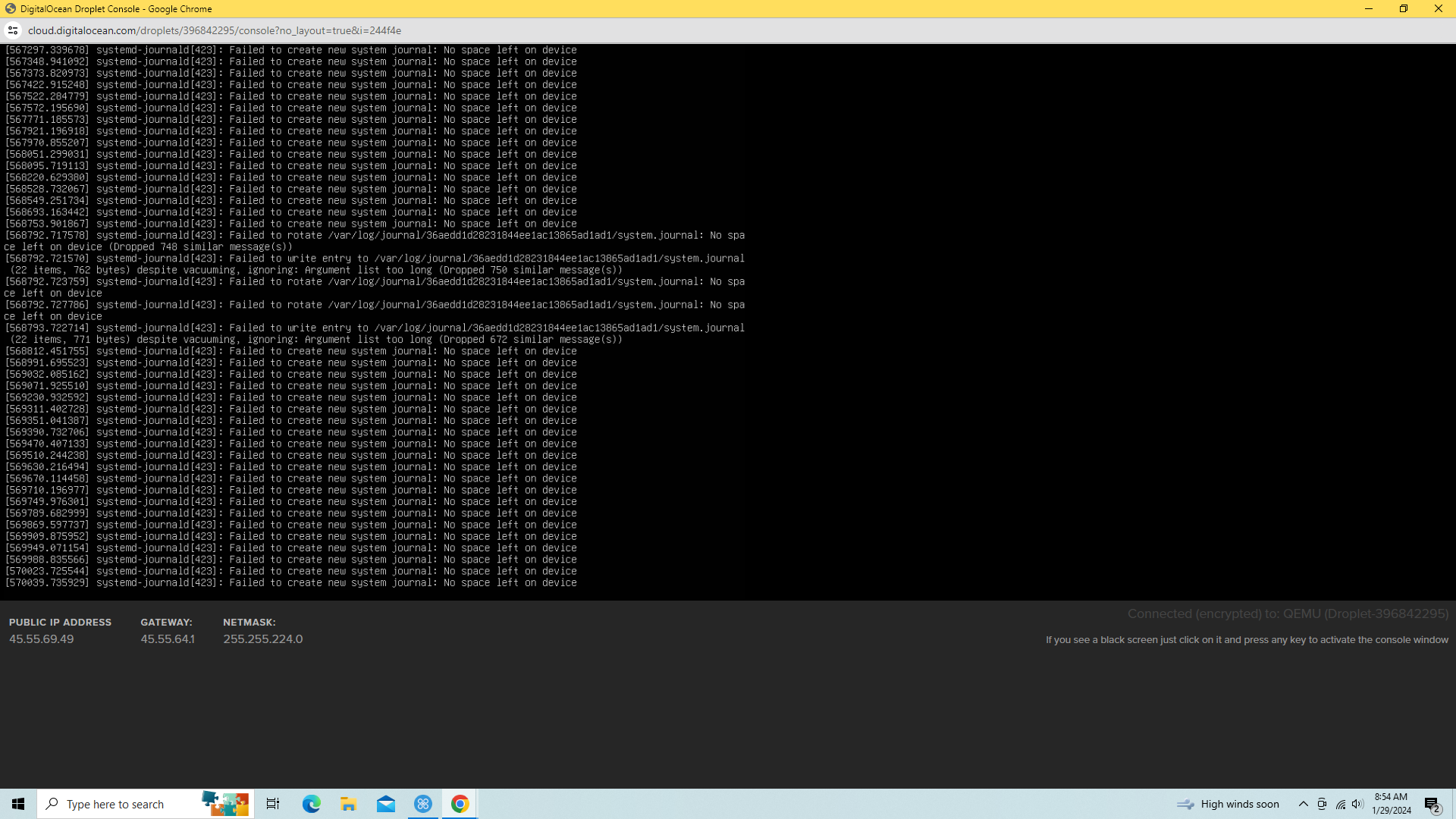
It seems that the job I had been running and reached 100% of the available memory (480gb) and WedODM did not stop gracefully. It locked up the entire machine - even preventing access to a console and root access. My only recovery option was to power cycle the server.
This graph is a 7 day period:

I was granted access to a recovery console which displayed this:
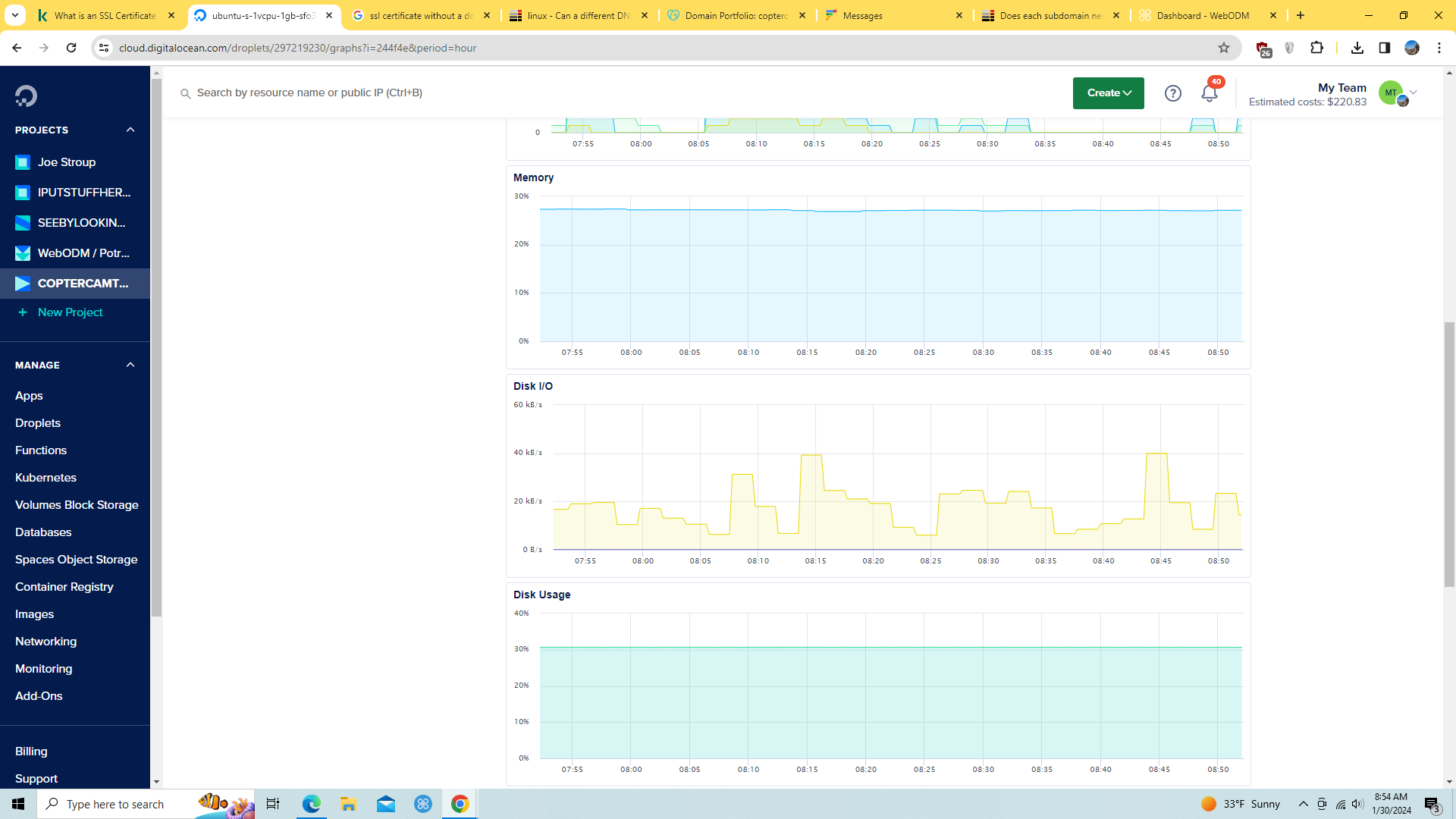
Over the week or so of running WebODM on this ubuntu/docker installation, it had at some points reclaimed some of the disk space it had consumed - as shown in the graph above. After my first day or two of running, I also increased the size of this server from 200gb to 480gb of storage.
I’ve only processed about 10 to 20 jobs. I believe I’d read something about WebODM cleaning up disk space - but it would seem it occurs too infrequently.
I started this server with 200gb - and within the first couple of jobs I found it was nearing 98% of available storage. So I resized the server to have 480gb. It would seem that if this server processed jobs on a regular basis, it would require multiple terabytes of storage - making it more expensive to run.
After power cycling the server, I stopped WebODM with the “webodm.sh stop” command, and re-started it with “webodm.sh start”.
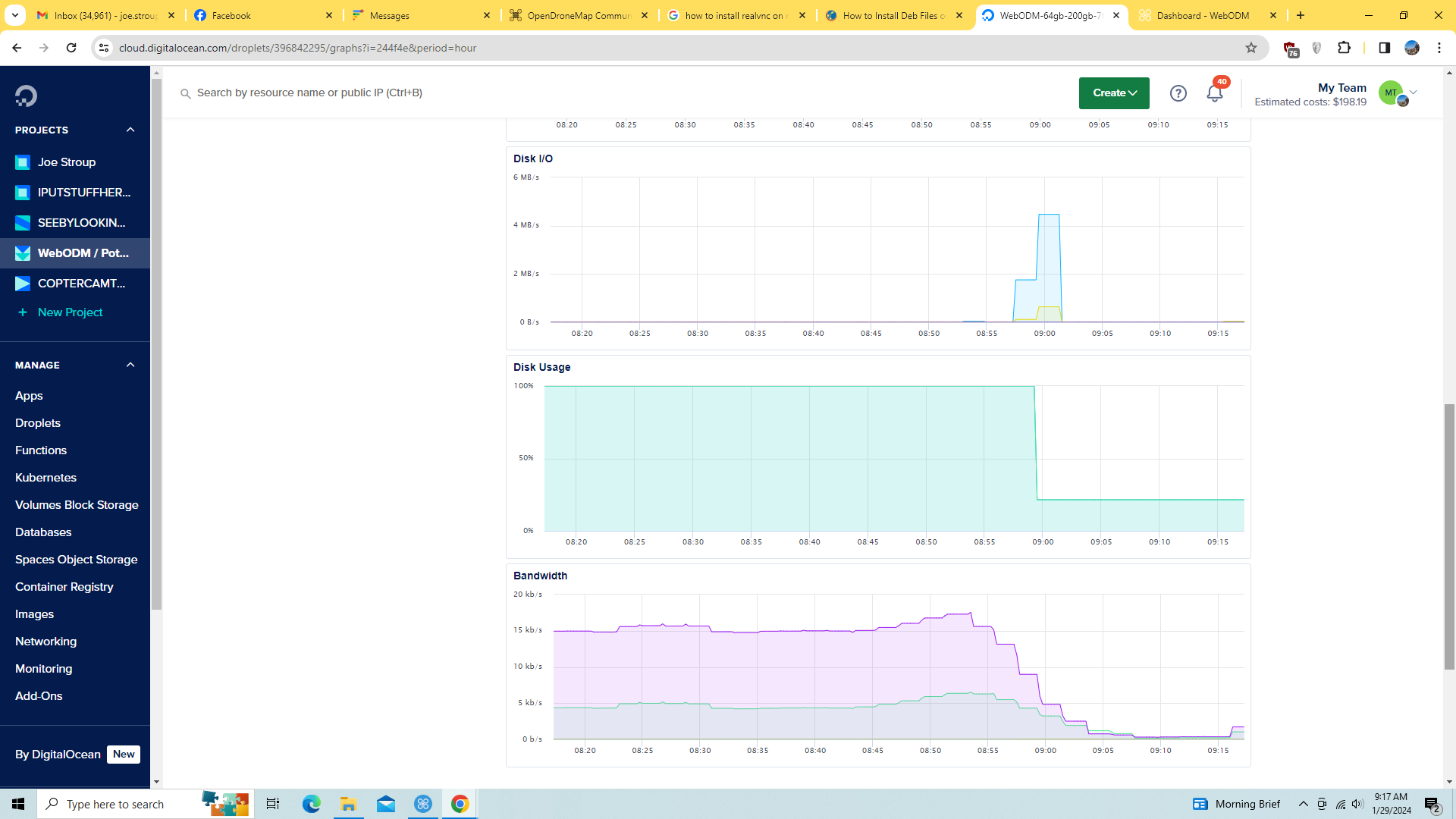
This process enabled WebODM to come back up - and it appears to immediately have discarded a great deal of its storage allocation.
This graph is for 1 hour period - when the system was recycled and WebODM recycled:
In my opinion, two changes to WebODM should be addressed:
-
WebODM should reclaim disk storage more frequently and aggressively when running in Docker. My Windows installation does not consume significant amounts of disk storage - so I’m guessing there’s something different about the Docker implementation.
-
WebODM should be aware of the available disk storage - and stop running gracefully with error messages when there’s a threat of running out of disk storage. There’s nothing wrong with a program crashing - as long as it crashes gracefully.
I have not researched this situation - so I don’t know if this situation has been documented and commented upon in the past. But it seems clear to me that until it is addressed, it would be problematic to use the Docker implementation of WebODM in any sort of production facillity.
Thank you!